ClickStack - The ClickHouse Observability Stack
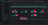
ClickStack is a production-grade observability platform built on ClickHouse, unifying logs, traces, metrics and session in a single high-performance solution. Designed for monitoring and debugging complex systems, ClickStack enables developers and SREs to trace issues end-to-end without switching between tools or manually stitching together data using timestamps or correlation IDs.
At the core of ClickStack is a simple but powerful idea: all observability data should be ingested as wide, rich events. These events are stored in ClickHouse tables by data type - logs, traces, metrics, and sessions - but remain fully queryable and cross-correlatable at the database level.
ClickStack is built to handle high-cardinality workloads efficiently by leveraging ClickHouse's column-oriented architecture, native JSON support, and fully parallelized execution engine. This enables sub-second queries across massive datasets, fast aggregations over wide time ranges, and deep inspection of individual traces. JSON is stored in a compressed, columnar format, allowing schema evolution without manual intervention or upfront definitions.
Features
The stack includes several key features designed for debugging and root cause analysis:
- Correlate/search logs, metrics, session replays, and traces all in one place
- Schema agnostic, works on top of your existing ClickHouse schema
- Blazing-fast searches & visualizations optimized for ClickHouse
- Intuitive full-text search and property search syntax (ex.
level:err), SQL optional. - Analyze trends in anomalies with event deltas
- Set up alerts in just a few clicks
- Dashboard high cardinality events without a complex query language
- Native JSON string querying
- Live tail logs and traces to always get the freshest events
- OpenTelemetry (OTel) supported out of the box
- Monitor health and performance from HTTP requests to DB queries (APM)
- Event deltas for identifying anomalies and performance regressions
- Log pattern recognition
Components
ClickStack consists of three core components:
- ClickStack UI (HyperDX) – a purpose-built frontend for exploring and visualizing observability data
- OpenTelemetry collector – a custom-built, preconfigured collector with an opinionated schema for logs, traces, and metrics
- ClickHouse – the high-performance analytical database at the heart of the stack
These components can be deployed together in a fully self-managed ClickStack Open Source setup, or split across managed and self-hosted environments. In Managed ClickStack, ClickHouse and the HyperDX UI are hosted and operated in ClickHouse Cloud, while users run only the OpenTelemetry Collector.
A browser-hosted version of the HyperDX UI is also available, allowing users to connect directly to existing ClickHouse deployments without deploying additional UI infrastructure.
To get started, visit the Getting started guide before loading a sample dataset. You can also explore documentation on deployment options and production best practices.
Principles
ClickStack is designed with a set of core principles that prioritize ease of use, performance, and flexibility at every layer of the observability stack:
Easy to set up in minutes
ClickStack works out of the box with any ClickHouse instance and schema, requiring minimal configuration. Whether you're starting fresh or integrating with an existing setup, you can be up and running in minutes.
User-friendly and purpose-built
The HyperDX UI supports both SQL and Lucene-style syntax, allowing users to choose the query interface that fits their workflow. Purpose-built for observability, the UI is optimized to help teams identify root causes quickly and navigate complex data without friction.
End-to-end observability
ClickStack provides full-stack visibility, from front-end user sessions to backend infrastructure metrics, application logs, and distributed traces. This unified view enables deep correlation and analysis across the entire system.
Built for ClickHouse
Every layer of the stack is designed to make full use of ClickHouse's capabilities. Queries are optimized to leverage ClickHouse's analytical functions and columnar engine, ensuring fast search and aggregation over massive volumes of data.
OpenTelemetry-native
ClickStack is natively integrated with OpenTelemetry, ingesting all data through an OpenTelemetry collector endpoint. For advanced users, it also supports direct ingestion into ClickHouse using native file formats, custom pipelines, or third-party tools like Vector.
Open source and fully customizable
ClickStack is fully open source and can be deployed anywhere. The schema is flexible and user-modifiable, and the UI is designed to be configurable to custom schemas without requiring changes. All components—including collectors, ClickHouse, and the UI - can be scaled independently to meet ingestion, query, or storage demands.
Architectural overview
The ClickStack architecture varies depending on how it is deployed. There are important architectural distinctions between ClickStack Open Source, where all components are self-managed, and Managed ClickStack, where ClickHouse and the HyperDX UI are hosted and operated in ClickHouse Cloud. While the core components remain the same in both models, the responsibility for hosting, scaling, and securing each component differs.
- Managed ClickStack
- Open Source ClickStack

Managed ClickStack runs entirely within ClickHouse Cloud, providing a fully managed observability backend while preserving the same ClickStack data model and user experience.
In this model, ClickHouse and the ClickStack UI (HyperDX) are hosted, operated, and secured by ClickHouse Cloud. Users are responsible only for running an OpenTelemetry Collector to send telemetry data into the managed service.
Managed ClickStack consists of the following components:
-
ClickStack UI (HyperDX)
The HyperDX UI is fully integrated into ClickHouse Cloud and managed as part of the service. It provides log search, trace exploration, dashboards, alerting, and correlation across telemetry types, with integrated authentication and access control. -
OpenTelemetry collector (self-managed)
Users run an OpenTelemetry Collector that receives telemetry data from their applications and infrastructure. This collector forwards data via OTLP to ClickHouse Cloud. While any standards-compliant OpenTelemetry Collector can be used, we strongly recommend the ClickStack distribution, which is preconfigured and optimized for ClickHouse ingestion and works out of the box with ClickStack schemas. -
ClickHouse Cloud
ClickHouse is fully managed in ClickHouse Cloud, serving as the storage and query engine for all observability data. Users do not need to manage clusters, upgrades, or operational concerns.
Managed ClickStack provides several key benefits:
- Automatic scaling of compute independent of storage
- Low-cost and effectively unlimited retention backed by object storage
- Independent read and write isolation using ClickHouse Cloud Warehouses
- Integrated authentication and access control
- Automated backups
- Security and compliance features
- Seamless upgrades with no operational downtime
This deployment model allows teams to focus entirely on observability workflows and instrumentation, without the overhead of operating ClickHouse or the ClickStack UI themselves.
For users deploying ClickStack in production, Managed ClickStack is the recommended option. See the Getting started guide for instructions on deploying ClickStack with ClickHouse Cloud.

Open Source ClickStack consists of three core components:
-
ClickStack UI (HyperDX)
A user-friendly interface built for observability. It supports both Lucene-style and SQL queries, interactive dashboards, alerting, trace exploration, and more—all optimized for ClickHouse as the backend. -
OpenTelemetry collector
A custom-built collector configured with an opinionated schema optimized for ClickHouse ingestion. It receives logs, metrics, and traces via OpenTelemetry protocols and writes them directly to ClickHouse using efficient batched inserts. -
ClickHouse
The high-performance analytical database that serves as the central data store for wide events. ClickHouse powers fast search, filtering, and aggregation at scale, leveraging its columnar engine and native support for JSON.
In addition to these three components, ClickStack uses a MongoDB instance to store application state such as dashboards, user accounts, and configuration settings.
A full architectural diagram and deployment details can be found in the Architecture section.
For users interesting in deploying Open Source ClickStack to production, we recommend reading the "Production" guide.
